密码学的实验报告,密码学真的难,DES完全是只知道思路但是写不出代码,最后到github参考了别人的代码才勉强修改完成,哈希稍微好些,可以选择,选了SHA-256以后简单的做了一个不加盐的函数,但是仍旧不是自己完全写出来的成果,ORZ…
过程很辛苦,查了很多资料,看了很多别人的实现方法,还是记录一下。
古典密码
凯撒密码
在密码学中,恺撒密码(英语:Caesar cipher),或称恺撒加密、恺撒变换、变换加密,是一种最简单且最广为人知的加密技术。它是一种替换加密的技术,明文中的所有字母都在字母表上向后(或向前)按照一个固定数目进行偏移后被替换成密文。例如,当偏移量是3的时候,所有的字母A将被替换成D,B变成E,以此类推。这个加密方法是以罗马共和时期恺撒的名字命名的,当年恺撒曾用此方法与其将军们进行联系。
凯撒安全性分析
由于英文只有26个字母,而且可以通过求余降幂,规模最大为26。完全可以暴力攻击。
加密
1 |
|
破解
1 |
|
程序运行截图
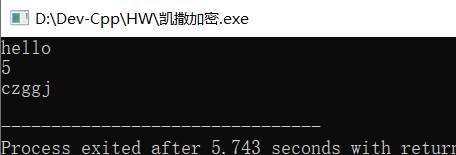

维吉尼亚密码
维吉尼亚密码(又译维热纳尔密码)是使用一系列凯撒密码组成密码字母表的加密算法,属于多表密码的一种简单形式。
维吉尼亚密码曾多次被发明。该方法最早记录在吉奥万·巴蒂斯塔·贝拉索( Giovan Battista Bellaso)于1553年所著的书《吉奥万·巴蒂斯塔·贝拉索先生的密码》(意大利语:La cifra del. Sig.Giovan Battista Bellaso)中。然而,后来在19世纪时被误传为是法国外交官布莱斯·德·维吉尼亚(Blaise De Vigenère)所创造,因此现在被称为“维吉尼亚密码”。
仿射密码的安全性分析
弗里德曼试验由威廉·F·弗里德曼(William F. Friedman)于1920年代发明。他使用了重合指数(index of coincidence)来描述密文字母频率的不匀性,从而破译密码。
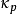
指目标语言中两个任意字母相同的概率(英文中为0.067),
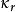
指字母表中这种情况出现的概率(英文中为1/26=0.0385),从而密钥长度可以估计为:
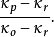
其中,观察概率为
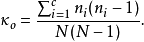
其中,c是指字母表的长度(英文为26),N指文本的长度,n1到n是指密文的字母频率,为整数。
此方法只是一种估计,会随着文本长度的增加而更为精确。在实践中,会尝试接近此估计的多个密钥长度。一种更好的方法是将密文写成矩阵形式,其中列数与假定的密钥长度一致,将每一列的重合指数单独计算,并求得平均重合指数。对于所有可能的密钥长度,平均重合指数最高的最有可能是真正的密钥长度。这样的试验可以作为卡西斯基试验的补充。
频率分析
一旦能够确定密钥的长度,密文就能重新写成多列,列数与密钥长度对应。这样每一列其实就是一个凯撒密码,而此密码的密钥(偏移量)则对应于维吉尼亚密码密钥的相应字母。与破译凯撒密码类似的方法,就能将密文破译。
柯克霍夫方法作为卡西斯基试验的改进,由奥古斯特·柯克霍夫(Auguste Kerckhoffs)提出。它将每一列的字母频率与转换后的明文频率相对应而得出每一列的密钥字母。一旦密钥中每一个字母都能确定,就能很简单地破译密文,从而得到明文。如果维吉尼亚字母表表格本身是杂乱而非按通常字母表顺序的话,那柯克霍夫方法就会无效,但卡西斯基试验和重复指数对于决定密钥长度仍旧是有效的。
加密
1 |
|
破解
1 | from string import ascii_lowercase as lowercase |
程序运行截图

分组密码
DES过程分析
所需参数
key:8个字节共64位密钥
data:8个字节共64位需要被加密的明文
初始置换
DES算法使用64位的密钥key将64位的明文输入块变为64位的密文输出块,并把输出块分为L0、R0两部分,每部分均为32位。初始置换规则如下:
1. 58,50,42,34,26,18,10,2,
2. 60,52,44,36,28,20,12,4,
3. 62,54,46,38,30,22,14,6,
4. 64,56,48,40,32,24,16,8,
5. 57,49,41,33,25,17, 9,1,
6. 59,51,43,35,27,19,11,3,
7. 61,53,45,37,29,21,13,5,
8. 63,55,47,39,31,23,15,7,
加密-迭代处理函数(F函数)
经过初始置换之后,进行16轮完全相同的运算,在运算过程中数据与密钥结合。
函数F的输出经过一个异或运算,和左半部分结合形成新的右半部分,原来的右半部分成为新的左半部分。
F函数:是由四步运算构成:密钥置换;拓展置换;S盒代替;P置换;
密钥置换—子密钥生成:DES算法由64位密钥产生16轮的48位子密钥。在每一轮的迭代过程中,使用不同的子密钥。
1. 把密钥的奇偶校验位忽略不参与计算,即每个字符的第8位,将6位密钥降为56位,让后根据选择置换PC-1将56位分成2块C0和D0各28位。
2. 将C0和D0进行循环左移变化(美伦循环作业的位数由轮数决定),变换后产生C1和D1,然后C1和D1合并,并通过选择置换pc-2生成子密钥k1(48位)
3. C1和D1再次经过循环左移变换,生成C2和D2,然后合并C2,D2,通过选择置换pc—2生成密钥K2(48位)
4. 以此类推,得到K16。最后一轮的左右两部分不交换,而是直接合并在一起R16L16,作为逆置换的输入块。
密钥置换选择1 PC—1
64位秘钥降至56位秘钥不是说将每个字节的第八位删除,而是通过缩小选择换位表1(置换选择表1)的变换变成56位。
1. 57,49,41,33,25,17,9,1,
2. 58,50,42,34,26,18,10,2,
3. 59,51,43,35,27,19,11,3,
4. 60,52,44,36,63,55,47,39,
5. 31,23,15,7,62,54,46,38,
6. 30,22,14,6,61,53,45,37,
7. 29,21,13,5,28,20,12,4
 再将56位秘钥分成C0和D0, 根据轮数,将Cn和Dn分别循环左移1位或2位.
再将56位秘钥分成C0和D0, 根据轮数,将Cn和Dn分别循环左移1位或2位.
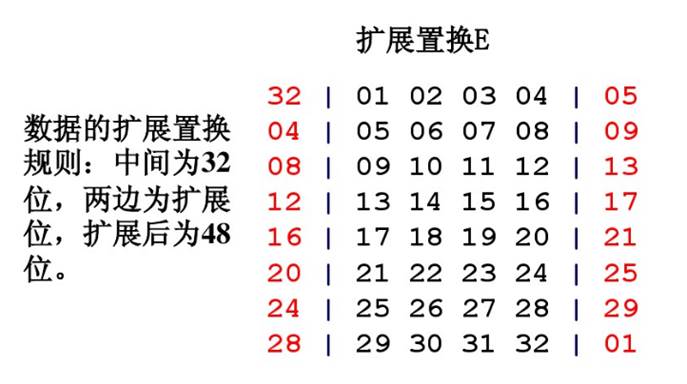
扩展置换E(E位选择表)
通过扩展置换E,数据的右半部分Rn从32位扩展到48位。扩展置换改变了位的次序,重复了某些位。扩展置换的目的:a、产生与秘钥相同长度的数据以进行异或运算,R0是32位,子秘钥是48位,所以R0要先进行扩展置换之后与子秘钥进行异或运算;b、提供更长的结果,使得在替代运算时能够进行压缩。扩展置换E规则如下:
S-盒代替(功能表S盒)
Rn扩展置换之后与子秘钥Kn异或以后的结果作为输入块进行S盒代替运算功能是把48位数据变为32位数据代替运算由8个不同的代替盒(S盒)完成。每个S-盒有6位输入,4位输出。所以48位的输入块被分成8个6位的分组,每一个分组对应一个S-盒代替操作。经过S-盒代替,形成8个4位分组结果。注意:每一个S-盒的输入数据是6位,输出数据是4位,但是每个S-盒自身是64位!!每个S-和是4行16列的格式,因为二进制4位是0~15。
8个S-盒的值如下:
1. // S1
2. 14, 4, 13, 1, 2, 15, 11, 8, 3, 10, 6, 12, 5, 9, 0, 7,
3. 0, 15, 7, 4, 14, 2, 13, 1, 10, 6, 12, 11, 9, 5, 3, 8,
4. 4, 1, 14, 8, 13, 6, 2, 11, 15, 12, 9, 7, 3, 10, 5, 0,
5. 15, 12, 8, 2, 4, 9, 1, 7, 5, 11, 3, 14, 10, 0, 6, 13,
6. // S2
7. 15, 1, 8, 14, 6, 11, 3, 4, 9, 7, 2, 13, 12, 0, 5, 10,
8. 3, 13, 4, 7, 15, 2, 8, 14, 12, 0, 1, 10, 6, 9, 11, 5,
9. 0, 14, 7, 11, 10, 4, 13, 1, 5, 8, 12, 6, 9, 3, 2, 15,
10. 13, 8, 10, 1, 3, 15, 4, 2, 11, 6, 7, 12, 0, 5, 14, 9,
11. // S3
12. 10, 0, 9, 14, 6, 3, 15, 5, 1, 13, 12, 7, 11, 4, 2, 8,
13. 13, 7, 0, 9, 3, 4, 6, 10, 2, 8, 5, 14, 12, 11, 15, 1,
14. 13, 6, 4, 9, 8, 15, 3, 0, 11, 1, 2, 12, 5, 10, 14, 7,
15. 1, 10, 13, 0, 6, 9, 8, 7, 4, 15, 14, 3, 11, 5, 2, 12,
16. // S4
17. 7, 13, 14, 3, 0, 6, 9, 10, 1, 2, 8, 5, 11, 12, 4, 15,
18. 13, 8, 11, 5, 6, 15, 0, 3, 4, 7, 2, 12, 1, 10, 14, 9,
19. 10, 6, 9, 0, 12, 11, 7, 13, 15, 1, 3, 14, 5, 2, 8, 4,
20. 3, 15, 0, 6, 10, 1, 13, 8, 9, 4, 5, 11, 12, 7, 2, 14,
21. // S5
22. 2, 12, 4, 1, 7, 10, 11, 6, 8, 5, 3, 15, 13, 0, 14, 9,
23. 14, 11, 2, 12, 4, 7, 13, 1, 5, 0, 15, 10, 3, 9, 8, 6,
24. 4, 2, 1, 11, 10, 13, 7, 8, 15, 9, 12, 5, 6, 3, 0, 14,
25. 11, 8, 12, 7, 1, 14, 2, 13, 6, 15, 0, 9, 10, 4, 5, 3,
26. // S6
27. 12, 1, 10, 15, 9, 2, 6, 8, 0, 13, 3, 4, 14, 7, 5, 11,
28. 10, 15, 4, 2, 7, 12, 9, 5, 6, 1, 13, 14, 0, 11, 3, 8,
29. 9, 14, 15, 5, 2, 8, 12, 3, 7, 0, 4, 10, 1, 13, 11, 6,
30. 4, 3, 2, 12, 9, 5, 15, 10, 11, 14, 1, 7, 6, 0, 8, 13,
31. // S7
32. 4, 11, 2, 14, 15, 0, 8, 13, 3, 12, 9, 7, 5, 10, 6, 1,
33. 13, 0, 11, 7, 4, 9, 1, 10, 14, 3, 5, 12, 2, 15, 8, 6,
34. 1, 4, 11, 13, 12, 3, 7, 14, 10, 15, 6, 8, 0, 5, 9, 2,
35. 6, 11, 13, 8, 1, 4, 10, 7, 9, 5, 0, 15, 14, 2, 3, 12,
36. // S8
37. 13, 2, 8, 4, 6, 15, 11, 1, 10, 9, 3, 14, 5, 0, 12, 7,
38. 1, 15, 13, 8, 10, 3, 7, 4, 12, 5, 6, 11, 0, 14, 9, 2,
39. 7, 11, 4, 1, 9, 12, 14, 2, 0, 6, 10, 13, 15, 3, 5, 8,
40. 2, 1, 14, 7, 4, 10, 8, 13, 15, 12, 9, 0, 3, 5, 6, 11
P盒置换:
S-盒代替运算,每一盒得到4位,8盒共得到32位输出。这32位输出作为P盒置换的输入块。P盒置换将每一位输入位映射到输出位。任何一位都不能被映射两次,也不能被略去。经过P-盒置换的结果与最初64位分组的左半部分异或,然后左右两部分交换,开始下一轮迭代。P-盒置换表(表示数据的位置)共32位
1. 16,7,20,21,29,12,28,17,1,15,23,26,5,18,31,10,
2. 2,8,24,14,32,27,3,9,19,13,30,6,22,11,4,25,
逆置换
将初始置换进行16次的迭代,即进行16层的加密变换,这个运算过程我们暂时称为函数f。得到L16和R16,将此作为输入块,进行逆置换得到最终的密文输出块。逆置换是初始置换的逆运算。从初始置换规则中可以看到,原始数据的第1位置换到了第40位,第2位置换到了第8位。则逆置换就是将第40位置换到第1位,第8位置换到第2位。以此类推,逆置换规则如下
1. 40,8,48,16,56,24,64,32,39,7,47,15,55,23,63,31,
2. 38,6,46,14,54,22,62,30,37,5,45,13,53,21,61,29,
3. 36,4,44,12,52,20,60,28,35,3,43,11,51,19,59,27,
4. 34,2,42,10,50,18,58 26,33,1,41, 9,49,17,57,25,
解密
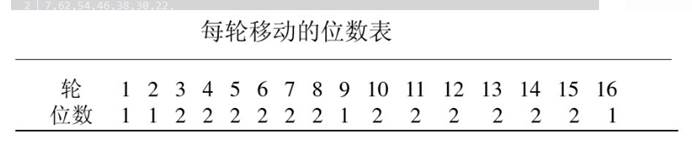
加密和解密可以使用相同的算法。加密和解密唯一不同的是秘钥的次序是相反的。就是说如果每一轮的加密秘钥分别是K1、K2、K3…K16,那么解密秘钥就是K16、K15、K14…K1。为每一轮产生秘钥的算法也是循环的。加密是秘钥循环左移,解密是秘钥循环右移。解密秘钥每次移动的位数是:0、1、2、2、2、2、2、2、1、2、2、2、2、2、2、1。
DES安全性分析
在相信复杂函数可以通过简单函数迭代若干圈得到的原则下,利用F函数及对合等运算,充分利用非线性运算。至今,最有效的破解DES算法的方法是穷举搜索法,那么56位长的密钥总共要测试256次,如果每100毫秒可以测试1次,那么需要7.2×1015秒,大约是228,493,000年。但是,仍有学者认为在可预见的将来用穷举法寻找正确密钥已趋于可行,所以若要安全保护10年以上的数据最好。现在多使用3DES加密。
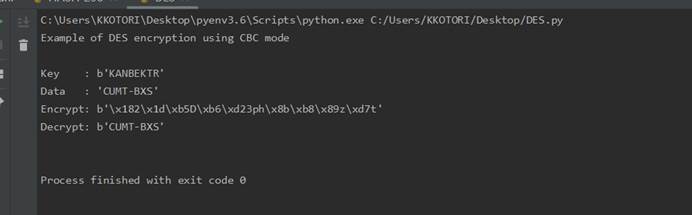
加密&解密
1 | import sys |
程序运行截图
序列密码
线性移位寄存器(LFSR)
线性反馈移位寄存器(linear feedback shift register, LFSR)是指,给定前一状态的输出,将该输出的线性函数再用作输入的移位寄存器。异或运算是最常见的单比特线性函数:对寄存器的某些位进行异或操作后作为输入,再对寄存器中的各比特进行整体移位。
线性反馈移位寄存器(LFSR)是一个产生二进制位序列的机制。这个寄存器由一个初始化矢量设置的一系列信元组成,最常见的是,密钥。这个寄存器的行为被一个时钟调节。在每个定时时刻,这个寄存器信元的内容被移动到一个正确的位置,这个排外的或这个信元子集内的内容被放在最左边的信元中。输出的一个位通常来自整个更新程序。LFSRs的应用包括产生伪随机数字,伪噪声序列,快速数字计算器和灰数序列。LFSR软件和硬件的执行是相同的。
实现
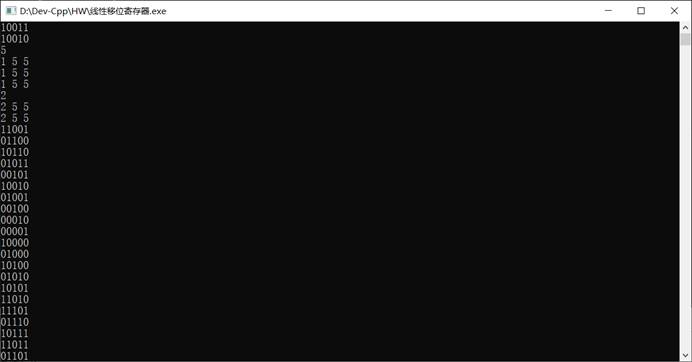
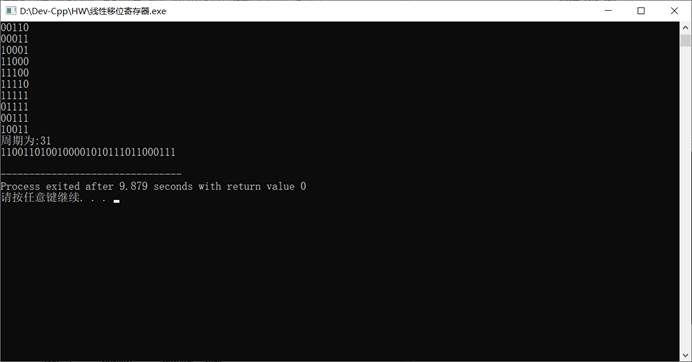
1 |
|
程序运行截图
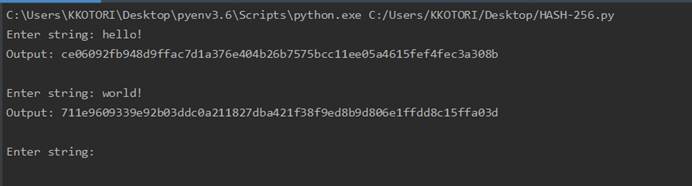
哈希函数
SHA-256分析
初始化
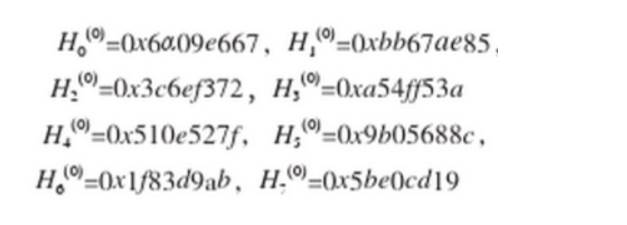
准备消息列表
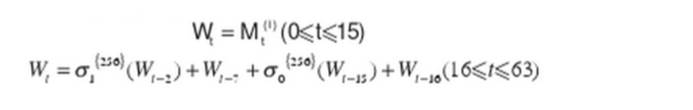
轮散列值初始化
用每一轮的散列值的中间结果初始化8个工作变量A、B、C、D、E、F、G、H。初始定义由H0(0)-H7(7)给出。
压缩函数
对于0≤t≤63,执行(即压缩函数):
T1=H+∑1{256}(e)+Ch(e,f,g)+Kt{256}+Wt
T2=∑0{256}(a)+Maj(a,b,c)
H=g g=h e=d+T1 d=c
c=b b=a a=T1+T2
每组的中间散列值计算方法
H0(i)=a+H0(i-j),
H1(i)=b+H1(i-j), H2(i)=c+H2(i-j),
H3(i)=d+H3(i-j), H4(i)=e+H4(i-j),
H5(i)=f+H5(i-j), H6(i)=g+H6(i-j),
H7(i)=h+H7(i-j)
这里i是指消息的第i个分组,将所有的分组处理完毕后,最后输出256比特的Hash值:
H0(N) | | H1(N)
| | H2(N) | | H3(N) | | H4(N)
| | H5(N) H6(N) | | H7(N)
算法中使用的6个逻辑函数:

SHA-256安全分析
Hash函数的安全性很大程度上取决于抗强碰撞的能力,即攻击者找出两个涓息M和MtM≠Mt,使得H(M)=HMt ,因此,评价一个Hash函数的安全性,就是看攻击者在现有的条件下,是否可以找到该函数的一对碰撞。目前已有的对Hash函数攻击的方法包括生日攻击、彩虹表攻击、差分攻击等。
实现
1 | class SHA256: |
程序运行截图
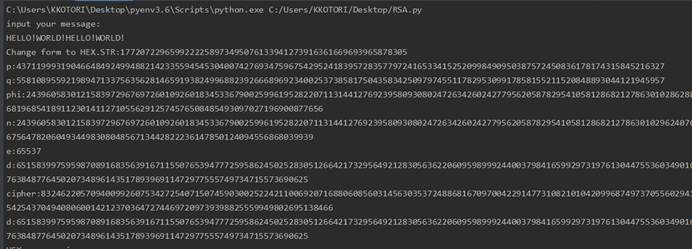
RSA
基于RSA的数字签名
用RSA进行数字签名
在RSA中,被签名的消息,密钥以及最终生成的签名都是以数字形式表示的,需要实现对文本编码成数字。用RSA生成签名的过程可以用下面的公式来表达。

这里使用的D和N就是签名者的私钥。签名就是对消息的D次方求mod N的结果,也就是说将消息和自己相乘D次,然后再求N的模数,最后求得的数就是签名。
用RSA验证签名
RSA的签名验证过程可用下列公式来表达:

这里所使用的E和N就是签名者的公钥。接收者计算签名的E次方并求mod N,得到“由签名求得的消息”,并将其发送过来的签名内容进行对比,如果两者一致,则签名验证成功,否则签名验证失败。
RSA签名生成和验证过程如图:

A,B之间进行签名
1.首先,A对明文M进行哈希加密,得到H(M),然后将H(M)^d mod N 求出签名值S;
2.A将M和s一齐发送给<spanlang=EN-US>B;
3.B收到消息后,首先将明文M进行哈希加密。然后判断H(M)=s^e(mod n)是否成立。如果成立则签名成功。
注:d,e,n都是rsa加密算法中的参数。
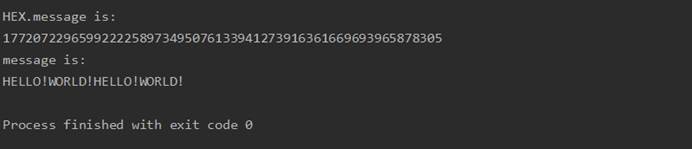
实现
1 |
|
程序运行截图
综合实验
Alice想通过公共信道给Bob传输一份秘密文件(文件非常大),又知道,很多人和机构想得到这份文件。如果你是Alice,你应该怎样做?请设计一个方案,并编程实现。
程序没编,但是思路想好了。
具体思路:
1.首先,A要发送的明文为M,A选择DES加密,则先对明文进行DES加密,则加密后的密文为C。
2.为了防止有人伪造A对B发送消息,则A对密文C进行基于RSA的数字签名。首先确定RSA的私钥d,公钥e,n;
3.首先A对密文进行哈希函数得到H(C),然后通过RSA的私钥D进行消息的“解密”,即Si=H(Ci)^d(mod n),随后 A将C与S发送给B。
4.B收到A发送过来的(C,S)之后,进行消息的验证。首先B先计算C对应的哈希值,并且与Si^e(mod n)比较是否同余,如果相同,则说明B收到的就是来自A发送的消息,发送过程中没有人进行消息的篡改和伪造。
5.B然后应用DES的解密算法和密钥进行解密,则得到明文M。